← Back to Index
我们经常需要了解一个指令典型的执行时间,下面提供了两种方式来查询
==1, 通过查看PDF文档 x86指令速查==
==2, 另一个在线的文档也可以查询: instlatx64 (atw.hu)==
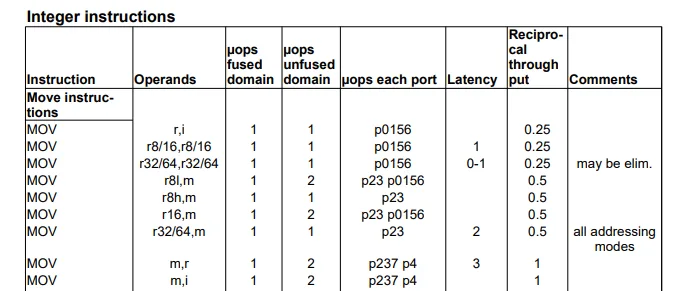
下面展示的是PDF文档中表格的格式: > [!NOTE] 省时! >
如果只关注指令执行时间,那么Latency
是你需要关注的列
- Instruction (指令):
这一列列出了具体的汇编指令,这里都是
MOV指令,也就是数据传输指令。
- Operands (操作数):
这一列表示指令的操作数类型。例如,
r,i表示一个寄存器和一个立即数,r8/m表示一个8位寄存器或内存位置等。
- uops fused domain (微操作数 - 融合域):
这一列显示了执行这个指令时,在处理器的融合域内生成的微操作数(uops)数量。融合域是指处理器的一个阶段,其中多个微操作数可以融合成一个。
- uops unfused domain (微操作数 - 非融合域):
这一列显示了在非融合域内生成的微操作数数量。在非融合域中,每个微操作数单独处理。
- uops each port (每个端口的微操作数):
这一列显示了微操作数通过处理器的不同执行端口(如
p0156、p23、p237等)执行的情况。处理器通常有多个执行端口,并行处理不同的微操作数。
- Latency (延迟):
这一列显示了指令的延迟时间,以时钟周期为单位。延迟是指从指令发出到其结果可以被后续指令使用的时间。
- Reciprocal throughput (逆吞吐量):
这一列显示了指令的逆吞吐量,即执行一次该指令平均需要的时钟周期数。数值越小,吞吐量越高。
- Comments (备注):
这一列包含对指令的额外说明。例如,有些指令可能在特定条件下被消除(eliminated)。
这些列的信息可以帮助程序员和系统架构师了解处理器如何执行特定的指令,进而进行代码优化。
如果你想知道一个指令的执行时间,你应该关注
Latency 这一列。
- Latency(延迟)
表示从指令开始执行到结果准备好可以被下一条指令使用所需要的时间,通常以时钟周期(clock
cycles)为单位。这是指令的执行时间。
- Reciprocal Throughput(逆吞吐量)
则表示平均每执行一条该指令所需的时间,如果你连续执行多条相同的指令,吞吐量通常更能反映处理器执行指令的效率,而不是单条指令的执行时间。
因此,对于单条指令的执行时间,Latency
是你需要关注的列。