linux内存管理(1)-基础
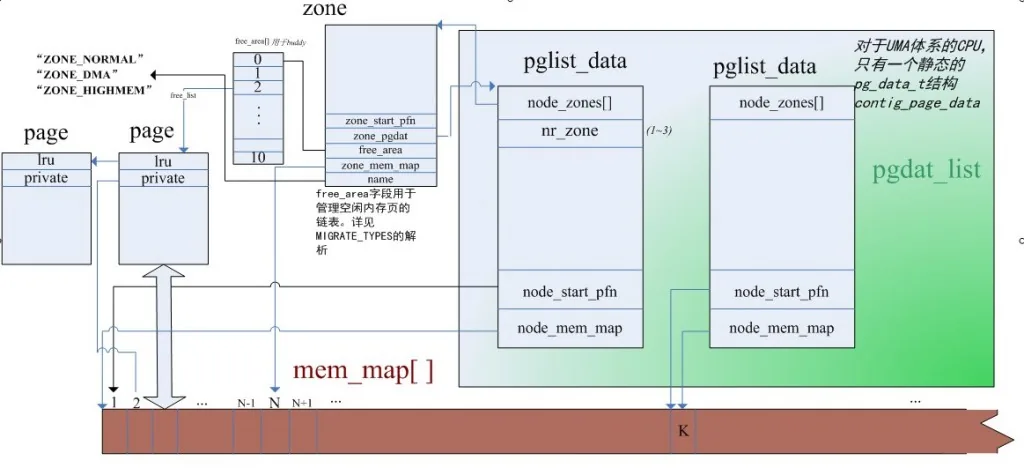
| 成员 | 作用 |
|---|---|
| unsigned long flags | 一组标志,也对页框所在的管理区进行编号 |
| atomic_t _count | 该页被引用的次数 |
| atomic_t _mapcount | 页框中页表项数目,如果没有则为-1 |
| struct list_head lru | 管理page忙碌/空闲链表(inactive_list/active_list),protected by zone->lru_lock ! |
| 成员 | 作用 |
|---|---|
| struct free_area free_area[MAX_ORDER] | 标识出管理区中的空闲页框块(buddy system) |
| struct pglist_data *zone_pgdat | 该zone的一些属性,包括指向各个node_zone指针等 |
| unsigned long zone_start_pfn | zone start page frame number,zone在mem_map数组中的起始页号。/ zone_start_pfn == zone_start_paddr >> PAGE_SHIFT / |
| 成员 | 作用 |
|---|---|
| struct zone node_zones[MAX_NR_ZONES] | 节点中管理区描述符数组 |
| struct zonelist node_zonelists[MAX_ZONELISTS] | 页分配器使用的zonelist数据结构的数组 |
| int nr_zones | 节点中管理区的个数 |
| struct page *node_mem_map | 节点中页描述符的数组 |
| unsigned long node_start_pfn | 节点中第一个页框的下标 |
初始化调用路径:
free_area_init_node()
alloc_node_mem_map()
mem_map = NODE_DATA(0)->node_mem_map;
1,vmalloc 申请返回的地址在vmalloc_start到vmalloc_end之间。其中,vmalloc_start在虚拟地址:
3G+physic memory length + 8G(gap)
vmalloc_end位置在虚拟地址:
4G -128K(专用页面映射)
2,kmalloc对应于kfree,可以分配连续的物理内存;
3,vmalloc优先使用高端物理内存,但性能上会打些折扣。
vmalloc分配的物理页不会被交换出去;
vmalloc使用的是vmlist链表,与管理用户进程的vm_area_struct要区别,而后者会swapped。
1,kmalloc申请返回内核虚拟地址,这个虚拟地址与实际的物理地址之间存在偏移量0XC000_0000,可用用virt_to_phys() 得到对应的物理地址。
3G~physic
2,vmalloc对应于vfree,分配连续的虚拟内存,但是物理上不一定连续。
3,kmalloc分配内存是基于slab,因此slab的一些特性包括着色,对齐等都具备,性能较好。物理地址和逻辑地址都是连续的。
4, kmalloc()是内核中最常见的内存分配方式,它最终调用伙伴系统的__get_free_pages()函数分配,根据传递给这个函数的flags参数,决定这个函数的分配适合什么场合,如果标志是GFP_KERNEL则仅仅可以用于进程上下文中,如果标志GFP_ATOMIC则可以用于中断上下文或者持有锁的代码段中。
kmalloc返回的线形地址是直接映射的,而且用连续物理页满足分配请求,且内置了最大请求数(2**5=32页)。
5,kmalloc 能够处理的最小分配是 32 或者 64 字节(依赖系统的体系所使用的页大小),小于128K
kmap()是主要用在高端存储器页框的内核映射中,一般是这么使用的:
使用alloc_pages()在高端存储器区得到struct page结构,然后调用kmap(struct *page)在内核地址空间PAGE_OFFSET+896M之后的地址空间中(PKMAP_BASE到FIXADDR_STAR)建立永久映射(如果page结构对应的是低端物理内存的页,该函数仅仅返回该页对应的虚拟地址)
kmap()也可能引起睡眠,所以不能用在中断和持有锁的代码中
不过kmap 只能对一个物理页进行分配,所以尽量少用。
使用kmap的原因:
对于高端物理内存(896M之后),并没有和内核地址空间建立一一对应的关系(即虚拟地址=物理地址+PAGE_OFFSET这样的关系),所以不能使用get_free_pages()这样的页分配器进行内存的分配,而必须使用alloc_pages()这样的伙伴系统算法的接口得到struct *page结构,然后将其映射到内核地址空间,注意这个时候映射后的地址并非和物理地址相差PAGE_OFFSET。
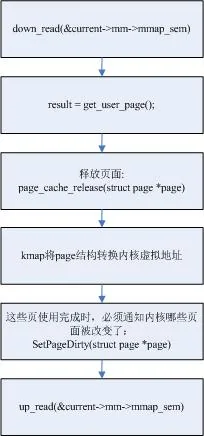
用于从用户空间获取缓冲区地址(页对齐),直接进行IO操作。通常用于大数据量的操作,如DMA。
其访问流程如下:
 编辑
编辑
有三个作用:
1,行为修饰 使用指定的方法分配内存。例如GPF_WAIT,可睡眠;GPF_IO,可启动磁盘。
2,区修饰 标识从哪个分区分配内存
3,类型修饰 例如GFP_KERNEL=>__FGP_WAIT | __GFP_IO | __GFP_FS,指定所需行为和区描述符。
#define MIGRATE_UNMOVABLE 0
#define MIGRATE_RECLAIMABLE 1
#define MIGRATE_MOVABLE 2
#define MIGRATE_PCPTYPES 3 /* the number of types on the pcp lists */
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* can't allocate from here */
#define MIGRATE_TYPES 5对伙伴系统的改进,减少系统碎片。
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};每一个free_area包含多个链表,其中每一个链表中的内存页面按照其自身是否可以释放或者迁移被归为一类,于是凡是请求“不可迁移”页面的分配请求全部在free_list[MIGRATE_UNMOVABLE]这条链表上分配,和老版本一样,系统中有10个free_area代表大小为2的N次幂个不同页面的集合。这种归类可以最小化内存碎片。