排序是我们日常编程中经常会遇到的一种算法。在程序语言的入门阶段,排序是掌握语言技巧的一种重要方式。我们通常会讨论排序的复杂度来判定排序函数的效率,在大规模数据的情况下,当然是成立的。不过,在实际过程中,我们有时候并不会涉及大量数据的比较操作。下面展示的这个案例,仅对50个整数进行排序。排序函数在运行过程中是一个相对耗时的操作,在我们的系统中,排序50个整数需要耗费大约2微秒!
排序的本质是什么?这2微秒花费在哪里了?
本文基于实际的性能评测数据,总结针对 std::sort
及高频排序调用场景下的几种优化思路。
在排序比较时,会涉及大量的内存搬移。内存操作是CPU执行缓慢的一个重要因素,所以,在排序过程中,我们希望CPU可能尽可能少的参与数据移动。
在我们系统的关键路径上,有一个对50个128比特整数排序的函数。128位的整数在工程实践中用到很少,看到类似的数据我们不经会想:系统中为什么会有这么大的数呢? 通过分析,这128比特并不表示物理世界的某种计数,仅仅是信息拼凑以后按照优先级的排序. 在进行一系列的数据合并以后,我们将放置在128比特中的信息“压缩”到64比特里面。
优化实践: - 重新审视数据128比特的构成。原本的
TdMetric(uint64_t)
或者优先级变量内部可能大量存在无用的留白,例如包含
sizeSubPrio(uint32_t),
sizeSubPrioX(uint16_t), sizeType(uint8_t),
sizeReqClassPriority(uint8_t) 的各种聚合。 -
按需压缩字段并缩减宽度,将拼凑出的 128-bit 优化至
64-bit。 -
效果:经过瘦身并在性能追踪器(Intel PT /
Callgrind)对比中测试,即便排列的元素极其稀少(最多 50
个成员对象),完全驻留在 L1 缓存的数据,整体的单次 sort 耗时依然从约
2029 ns 降低到了 1815
ns。在关键路径上这种压榨有显著收益。
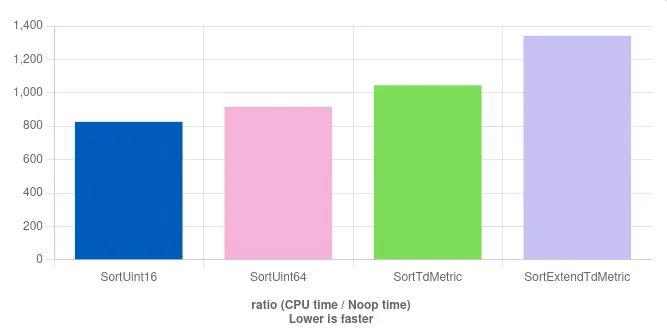
下面我们尝试对不同的数据宽度的整形进行排序(uint16_t, uint64_t, 128 bit, 256bit), 测试对50个元素进行排序。可以看到,即便L1可以存储所有的元素的情况下,不同的数据宽度对排序结果仍有影响。
pdqsort)C++ STL 中 std::sort
通常使用的是混合式的内省排序(IntroSort),它非常全能,但在特定条件下并不一定能跑出极致性能。
优化实践: 如果项目中允许引入
boost,尝试使用 boost::sort
库中的排序算法,特别推荐
boost::sort::pdqsort(Pattern-defeating
quicksort)。pdqsort
代码内含了抵抗分支预测失败的技术,对 CPU
分支预测器非常友好;而且它本身内建对待“部分有序(Partially
Sorted)”情况的安全快排,表现很好。
不同算法在一组 50 个长类型变量成员排序的实验参照表现下: -
std::sort:平均约 1815 ns -
boost::sort::pdqsort:平均降至
1595 ns ~ 1630 ns(提速接近 15%) -
其它测试:如果数据主要是整型值,也可以使用基数排序衍生物如
boost::sort::spreadsort::integer_sort。
仅仅通过替换一个
#include <boost/sort/pdqsort/pdqsort.hpp>
并换掉函数名,就可以免费获得更强的分支预测友好度。
is_sorted在许多生产环境和高频调用点中,由于数据在前一次排序和当前调用的中间可能仅发生了轻微的相对大小变异,也就是数据只有少量陷入乱序甚至直接大部分原封未动本身有序。
优化实践: 结合 std::is_sorted
进行前置安全判断或者配合
std::rotate。我们以一段经典的混合排列方式为例:
const auto comp = [](const auto& lhs, const auto& rhs) {
return lhs.getExtendedTdMetric() > rhs.getExtendedTdMetric();
};
// 1. 如果已经有序,提早直接退出 (极大规避 sort 重排)
if (std::is_sorted(elements.begin(), elements.end(), comp)) {
return;
}
// 2. 找到第一个无序的位置下标
auto unsorted_from = std::is_sorted_until(elements.begin(), elements.end(), comp);
const auto sorted_count = std::distance(elements.begin(), unsorted_from);
const auto total_count = elements.size();
// 3. 启发式决策拦截:如果超过很大比例的元素(比如 80%)都是有序的,就只局部插入乱序队列
if (sorted_count > total_count * 4 / 5) {
for (auto it = unsorted_from; it != elements.end(); ++it) {
auto key = *it;
auto insert_pos = std::upper_bound(elements.begin(), it, key, comp);
std::rotate(insert_pos, it, it + 1);
}
} else {
// 4. 数据太乱,回退到全量排序(或者也可以用 pdqsort)
boost::sort::pdqsort(elements.begin(), elements.end(), comp);
}效果:当面临大部分调度序列基本盘已经锁定的场景,这种做法把高成本的全量重排直接降格到了局部折半查表,对长尾和尾部干扰能显著消除尖峰处理延时。
对于含有大规模或承载负载较重的对象,每次对数组进行交换和替换对象实例,都会带来无谓的指令损耗和深层拷贝。这同样是经典的代码坏味道之一。
优化实践: 确保排列不搬运对象 Payload,而是单纯只整理并“排序”出它们的序号、下标信息。
// 初始化一个自然数索引映射的数组
std::array<size_t, ARRAY_SIZE> indices;
std::iota(indices.begin(), indices.end(), 0);
// 基于业务结构的特性,仅打乱并排列 indices 的大小,不去搬移元素实体本身
std::sort(indices.begin(), indices.end(),
[&](size_t i, size_t j) {
return testArray[i].metric < testArray[j].metric;
});
// TODO(或依据具体需求)
// 若在之后还有大量依据重排后的结果进行内存顺序遍历的刚需,可能会触发长链路散列访问,
// 则可以通过下标将其内存连续化再用;否则直接使用 `indices[0]`、`indices[1]` 即安全可出结果。std::sort
最大的浪费之一在于:它总是排出一个完全有序的序列,但有时候根本不需要严格有序。
在调度器中,一个典型的场景是:从候选列表中找出最优的前 K 个 UE 进行调度,取出这些 UE 后剩余候选者的顺序并不重要。此时对全部 N 个候选排序,做了大量无意义的比较和交换。
std::partial_sort:只排好前
K 个std::partial_sort(begin, begin+K, end, comp) 保证
[begin, begin+K) 区间是有序的前 K
个最优元素,后面的元素顺序不保证,时间复杂度为 O(n
log K) 而不是 O(n log n)。
// 只需要前 K 个最优候选,不关心其余元素的顺序
std::partial_sort(candidates.begin(),
candidates.begin() + K,
candidates.end(),
comp);
// 现在 [begin, begin+K) 就是排好序的前 K 个基于 14044 特性的实际 Callgrind 数据:
| 优化手段 | 函数 | 优化前(Ir/call) | 优化后 | 减少 |
|---|---|---|---|---|
partial_sort for selectBestKList |
selectBestKList |
3890 | 1596 | -2294(降低 59%) |
partial_sort for selectBestNList |
selectBestNList |
3202 | 2363 | -839(降低 26%) |
当 K 远小于 N 时,partial_sort
在内部使用堆排序对前 K
个元素建堆,仅扫描一次剩余元素。K 越小,相对 std::sort
的收益越大。
std::nth_element +
局部 sort:两步走如果场景是”先找出前 K 个,再对这 K 个排序”,可以拆成两步:
std::nth_element:O(n) 将第 K 大的元素放到
begin+K 位置,并保证 [begin, begin+K)
的所有元素都优于它,但 K
个元素自身不保证有序。std::sort:O(K log K),由于 K
极小,几乎没有额外开销。// 第一步:O(n) 线性将前 K 个最优候选划出来(无序)
std::nth_element(candidates.begin(),
candidates.begin() + K,
candidates.end(),
comp);
// 第二步:仅对这 K 个排序,K 很小,几近免费
std::sort(candidates.begin(), candidates.begin() + K, comp);实测 selectBestNList Ir/call 从 2363 降至
1740(约减少 26%)。
选择建议: - 只需前 K
个且需要有序:直接用 partial_sort。 -
只需前 K 个但不要求内部有序(如聚合统计):用
nth_element 单步,O(n) 最快。 - K / N
比值较大(比如超过 50%):两种方案优势缩小,直接 sort
反而更简单。
在极其苛刻的高频调用(微秒乃至纳秒级敏感)场景下,底层函数的优化是架构之外必不可少的精雕细琢。C++ 下的集合内部排列,有 5 个大方向可以挖掘:
pdqsort。is_sorted 与局部置位组合。partial_sort 或 nth_element 而不是全量
sort。使用性能测试(如 intelpt 或
callgrind)对执行前后的代码块进行
Profiling,用数据讲话永远是优化工作中最好的导师。